
Machine Learning Explained: What It Is & How It Works
Machine learning is a subset of artificial intelligence that enables computers to learn from data and improve their performance on specific tasks without being explicitly programmed. Rather than following rigid, hand-coded instructions, machine learning systems identify patterns in data and use those patterns to make predictions or decisions. This technology powers everything from Netflix recommendations to voice assistants like Siri, from fraud detection in banking to medical diagnosis assistance in healthcare.
Understanding machine learning has become essential in today’s data-driven world. Organizations across every industry are leveraging these systems to automate processes, gain insights from vast amounts of data, and create personalized experiences for their customers. Whether you’re a business professional, a student, or simply a curious individual, grasping the fundamentals of machine learning helps you understand the technological forces shaping our modern world.
This guide breaks down machine learning into clear, digestible concepts. You’ll learn about the different types of machine learning, how these systems actually work, the key terminology you need to know, and real-world applications that demonstrate its impact. By the end, you’ll have a solid foundation for understanding this transformative technology.
Understanding the Fundamentals of Machine Learning
At its core, machine learning is about teaching computers to learn from examples rather than programming them with step-by-step instructions for every possible scenario. Traditional programming requires a human developer to write explicit rules: if X happens, do Y. Machine learning flips this approach by showing the computer many examples of inputs and desired outputs, then letting it discover the rules itself.
The process begins with data. This data can take many forms: images, text, numbers, audio, or any other type of information relevant to the task at hand. A machine learning model examines this data, finds patterns within it, and creates a mathematical representation of those patterns. This representation—often called a “model” or “trained model”—can then be used to make predictions on new, previously unseen data.
What makes machine learning particularly powerful is its ability to handle complexity and scale. When the number of possible rules becomes astronomical, or when the relationships between variables are too intricate for humans to code manually, machine learning excels. A human cannot reasonably write rules for recognizing faces in photos, but showing a neural network millions of labeled photos allows it to learn the features that define a face.
The field gained tremendous momentum in the 2010s due to three converging factors: the availability of massive datasets, increased computational power through GPUs, and algorithmic advances particularly in deep learning. Today, machine learning applications touch virtually every sector of the economy and continue to expand into new territories.
Types of Machine Learning
Machine learning approaches generally fall into three broad categories, each suited to different types of problems and data availability.
Supervised learning is the most common form and works like teaching a child with flashcards. You provide the algorithm with input data paired with the correct output, essentially giving it labeled examples to learn from. The system learns to map inputs to outputs by finding patterns in these labeled examples. Once trained, it can then predict outputs for new, unlabeled inputs. Common applications include email spam classification, where the model learns from thousands of emails marked as spam or not spam, and house price prediction based on features like square footage, location, and number of bedrooms.
Unsupervised learning works with data that has no labels or known outputs. The algorithm must find structure and patterns within the data itself. This is useful for discovering natural groupings, identifying anomalies, or reducing the complexity of data. Customer segmentation is a typical application: an e-commerce company might feed purchase history data to an unsupervised algorithm and discover that their customers naturally group into distinct categories such as bargain hunters, luxury buyers, or frequent small purchasers. Another common use is dimensionality reduction, where complex data is simplified while retaining its essential characteristics.
Reinforcement learning takes a different approach, inspired by how animals learn through trial and error. An agent learns to make decisions by interacting with an environment and receiving rewards or penalties based on its actions. Over time, the agent learns which actions maximize rewards. This approach has achieved remarkable results in game playing and robotics. AlphaGo, the program that defeated world champion Go players, used reinforcement learning to master the ancient game. In robotics, reinforcement learning enables machines to learn physical tasks like grasping objects or walking through trial and error in simulation or the real world.
How Machine Learning Actually Works
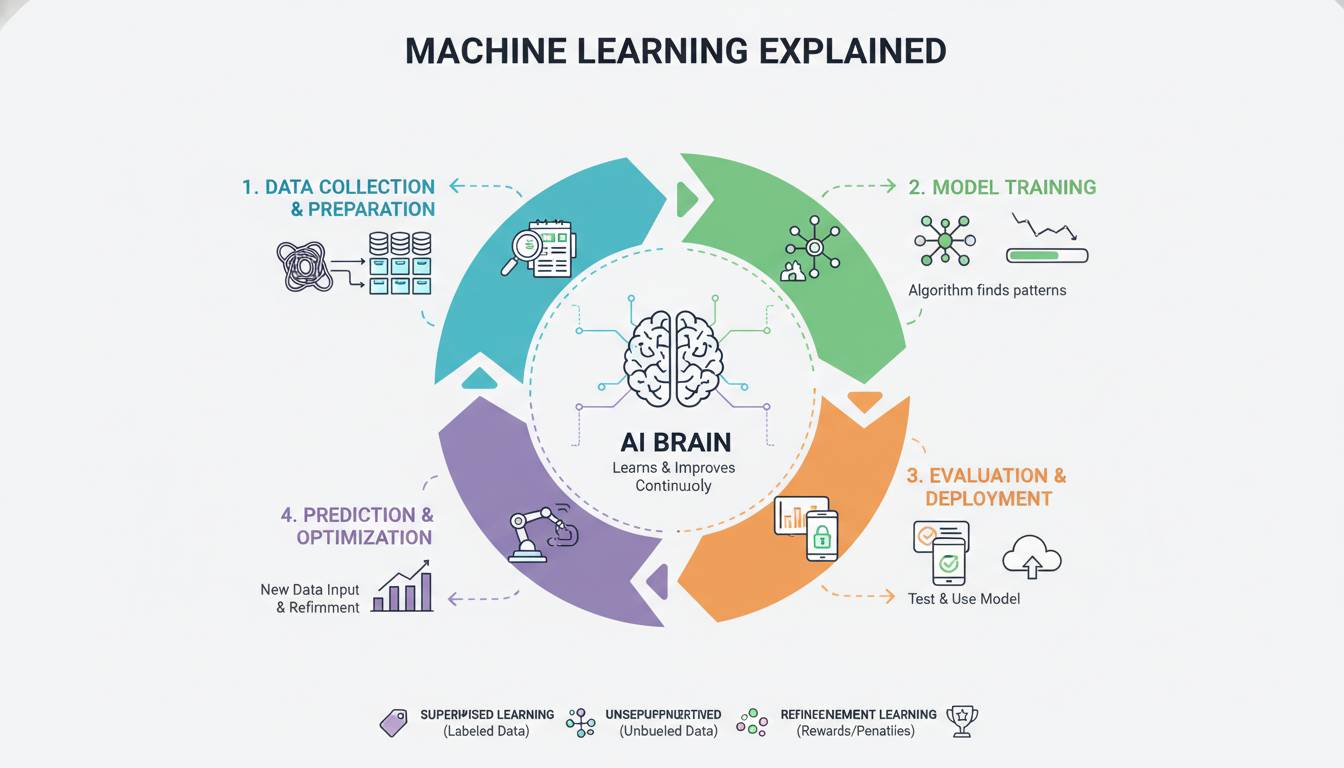
Understanding the machine learning workflow helps demystify how these systems function in practice. The process typically involves several distinct phases.
Data collection forms the foundation. The quality and quantity of data directly influence how well a model can learn. Relevant, representative, and accurately labeled data produces better models. In practice, data scientists spend significant time gathering, cleaning, and preparing data—often 60-80% of a project’s time according to industry surveys.
Data preprocessing transforms raw data into a format the algorithm can work with effectively. This includes handling missing values, normalizing numerical features, encoding categorical variables, and often reducing dimensionality to focus on the most informative aspects. A dataset of house listings might contain the number of bathrooms as numbers and the neighborhood as text; preprocessing converts both into numerical representations the algorithm can process.
Model training is where the learning happens. The algorithm examines the training data and adjusts its internal parameters to minimize errors in its predictions. In supervised learning, this means adjusting weights in a mathematical model to reduce the difference between predicted and actual outputs. The training process typically involves showing the model many examples repeatedly, gradually improving its performance.
Model evaluation measures how well the trained model performs on new, unseen data. This is crucial because a model that performs well on training data but poorly on new data has “overfit”—it memorized the training examples rather than learning generalizable patterns. Evaluation uses metrics appropriate to the problem type: accuracy, precision, recall, F1 score for classification tasks; mean squared error or R-squared for regression tasks.
Deployment and inference is where the model becomes useful in the real world. Once validated, the model is integrated into applications or systems where it processes new data and generates predictions. A fraud detection model deployed by a bank evaluates transactions in real-time, flagging suspicious activity for review.
Key Concepts and Terminology
Several core concepts appear throughout machine learning discussions and understanding them provides a foundation for deeper exploration.
Features are the individual measurable properties of the data being analyzed. In a dataset of houses, features might include square footage, number of bedrooms, year built, and distance to schools. Feature engineering—the process of selecting and transforming features—significantly impacts model performance.
Training data is the dataset used to teach the model. In supervised learning, this data includes both the inputs (features) and the correct outputs (labels). The model learns patterns from this data that it can apply to new situations.
Labels or targets are the correct answers in supervised learning. In a spam detection system, each email has a label of either “spam” or “not spam.” The model learns to predict these labels from the email content.
Overfitting occurs when a model learns the training data too well, including its noise and idiosyncrasies. An overfit model performs excellently on training data but poorly on new data. Conversely, underfitting happens when a model is too simple to capture the underlying patterns in the data, performing poorly on both training and new data.
Generalization refers to a model’s ability to perform well on data it hasn’t seen during training. The ultimate goal of machine learning is creating models that generalize effectively, making accurate predictions on real-world problems.
Bias-variance tradeoff describes the tension between two sources of error. High bias causes underfitting, while high variance causes overfitting. Finding the right balance produces models that generalize well.
Common Machine Learning Algorithms
Several algorithms form the toolkit that data scientists use to solve different types of problems.
Linear regression is the foundational algorithm for predicting continuous values. It finds the straight line (or plane in higher dimensions) that best fits the relationship between input features and a numerical output. Predicting house prices based on square footage and location uses linear regression.
Logistic regression handles classification problems, predicting categorical outcomes like spam or not spam, fraudulent or legitimate. Despite its name, it’s a classification algorithm that outputs probabilities.
Decision trees build flowchart-like models by splitting data based on feature values. Each split creates branches representing different outcomes, making the model’s decisions easy to interpret. Random forests combine multiple decision trees for greater accuracy.
Support vector machines find the optimal boundary (hyperplane) that separates different classes in the data. They work well with clear margins between classes and perform reliably across many domains.
Neural networks are inspired by biological brains and consist of layers of interconnected nodes (neurons). Deep learning uses neural networks with many layers to model extremely complex patterns. Convolutional neural networks excel at image processing, while recurrent neural networks handle sequential data like text and time series.
K-means clustering is an unsupervised algorithm that groups data into K distinct clusters based on similarity. It partitions data so that points within each cluster are as similar as possible to each other and as different as possible from points in other clusters.
Real-World Applications
Machine learning applications span virtually every industry, transforming how organizations operate and serve their customers.
In healthcare, machine learning assists in diagnosing diseases from medical imaging, predicting patient outcomes, discovering new drugs, and personalizing treatment plans. Algorithms can analyze X-rays, MRIs, and CT scans to detect conditions like cancer, diabetic retinopathy, and fractures—sometimes matching or exceeding human specialist performance.
Financial services rely heavily on machine learning for fraud detection, credit scoring, algorithmic trading, and risk assessment. Credit card companies process millions of transactions in real-time, flagging suspicious activity using models trained on patterns of fraudulent behavior.
E-commerce and retail use machine learning for product recommendations, inventory management, demand forecasting, and dynamic pricing. When Amazon suggests products or Netflix recommends your next show, sophisticated algorithms are working behind the scenes.
Transportation has been transformed by machine learning, particularly through autonomous vehicles. Self-driving cars use deep learning to interpret sensor data, recognize objects, and make driving decisions. Ride-sharing services optimize routing and pricing using predictive models.
Natural language processing enables machines to understand, interpret, and generate human language. Virtual assistants, machine translation, sentiment analysis, and text summarization all rely on machine learning techniques, particularly modern transformer-based models.
Getting Started with Machine Learning
For those interested in learning machine learning, numerous resources exist at every skill level.
Programming skills in Python have become the standard for machine learning development. Key libraries include scikit-learn for traditional algorithms, TensorFlow and PyTorch for deep learning, and pandas for data manipulation. Online platforms like Kaggle provide datasets for practice and competitions.
Mathematical foundations matter, particularly linear algebra, calculus, probability, and statistics. While you can start with high-level libraries that handle much of the math, understanding the underlying principles helps with model selection, debugging, and innovation.
Online courses from platforms like Coursera, edX, and Udacity offer structured learning paths from beginner to advanced levels. Many are taught by leading researchers and practitioners from top universities and companies.
Practical experience is invaluable. Start with simple problems: predict housing prices, classify iris flowers, or build a spam filter. Gradually tackle more complex projects as your skills develop. Participating in Kaggle competitions provides real-world practice with feedback.
Frequently Asked Questions
What is the difference between machine learning and artificial intelligence?
Artificial intelligence is the broader field of creating systems that can perform tasks requiring human intelligence. Machine learning is a specific approach within AI where systems learn from data rather than following explicit rules. All machine learning is AI, but not all AI involves machine learning—early AI systems used manually programmed rules.
Do I need powerful hardware for machine learning?
For learning and small projects, a standard computer works fine. Cloud platforms like Google Colab, AWS, and Azure provide free or low-cost access to powerful GPUs. For large-scale training, organizations use specialized hardware, but you can accomplish a tremendous amount with consumer-grade equipment or cloud credits.
How much data do I need for machine learning?
It depends on the problem complexity and algorithm. Simple problems with clear patterns may need hundreds of examples, while complex tasks like image recognition require millions. More data generally helps, but quality matters—clean, representative, well-labeled data often beats larger datasets with issues.
Is machine learning only for technical people?
No. While building models requires technical skills, using machine learning outputs doesn’t. Business analysts, managers, and professionals across fields work with machine learning results without needing to build models themselves. Understanding the concepts helps you ask better questions and make informed decisions about ML applications.
Can machine learning be biased?
Yes, machine learning can perpetuate or amplify biases present in training data. If historical hiring data reflects discrimination, a model trained on that data may reproduce those biases. Addressing bias requires careful data selection, fairness-aware algorithms, and ongoing monitoring—a critical area of research and practice.
Will machine learning replace human jobs?
Machine learning automates specific tasks rather than entire jobs. It excels at pattern recognition and prediction on structured data, but many roles require creativity, complex interpersonal skills, ethical judgment, and unstructured problem-solving that remain challenging for AI. The technology more often augments human capabilities than replaces workers entirely.
Conclusion
Machine learning has evolved from an academic research topic into a transformative technology affecting every aspect of modern life. Understanding its fundamentals—how systems learn from data, the different approaches available, and how they’re applied—provides valuable insight into the forces shaping our world.
The field continues advancing rapidly, with new algorithms, techniques, and applications emerging regularly. What remains constant is the core principle: by finding patterns in data, machines can make predictions and decisions that would be impossible to program manually. Whether you pursue technical mastery or simply want to understand the technology around you, machine learning offers a fascinating area of study with relevance that will only grow in the years ahead.




